wie die Verfügbarkeit von IT-Netzen und IT-Diensten sichergestellt wird
Die Schlüsseltechnologie eines funktionierenden und erfolgreichen Unternehmens ist die IT.
Davon abhängig ist die reibungslose in- und externe Kommunikation der Mitarbeiter.
Kommt es zu Ausfällen von einzelnen Komponenten, kann dies zu Ausfällen ganzer Unternehmenteilen führen. Sind dann kritische Bereiche betroffen, kann es zu erheblichen Verlusten bis hin zur Existenzbedrohung für das Gesamtunternehmen führen. Aus diesem Grund ist eine hohe Verfügbarkeit sämtlicher Systeme wichtig.
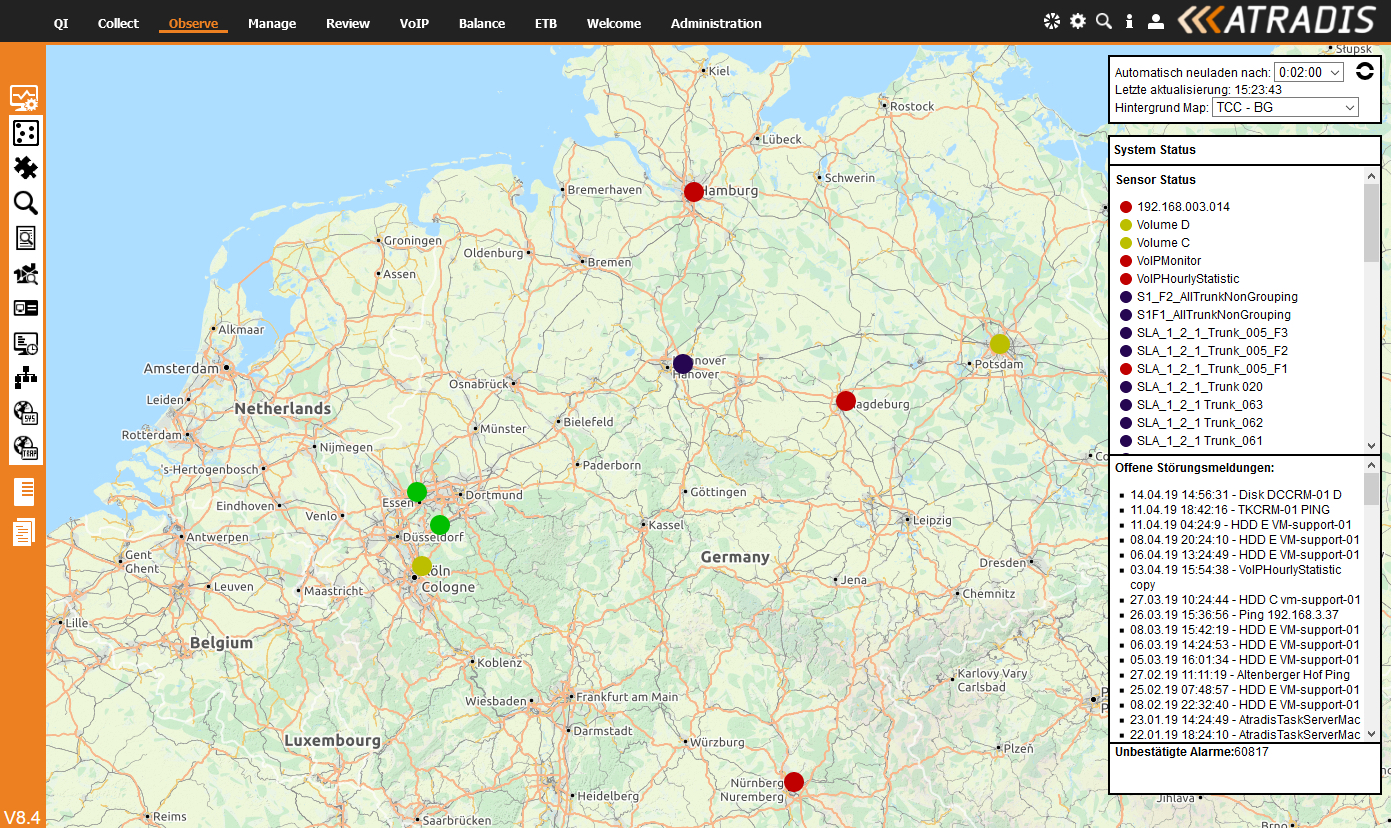
Wie kann man Abweichungen von den Sollvorgaben erkennen und abstellen?
Nun sollte man annehmen, dass moderne IT-Systemtechnik über ein integriertes Managementsystem verfügt, dieses aufkommende Störungssituationen erkennt und Maßnahmen einleitet. Im Einzelfall ist dies korrekt, allerdings wird nicht mit der Gesamtproblematik gerechnet. Selbst wenn alle IT Systeme in einem Unternehmen über entsprechende Tools verfügen, ist damit noch nicht sichergestellt, dass in kritischen Situationen alle Informationen an einer Stelle zusammenlaufen. Dies ist aber nötig, um einen Gesamtüberblick zu schaffen, der es den Verantwortlichen ermöglicht, schnell faktenbasierte Entscheidungen zu treffen und Maßnahmen ein zu leiten.
Monitoringsysteme, die die Komponenten in einer IT überwachen, sind am Markt verfügbar. Allzu oft werden hier aus der Not heraus schnelle Entscheidungen getroffen, um dann im Betrieb fest zu stellen das das gewünschte Ergebnis (in diesem Fall: ein umfassender, herstellerübergreifender Überblick über den Zustand aller IT Komponenten und Dienste) nicht gewährleistet ist.
Als zielführende Herangehensweise empfiehlt es sich darüber nach zu denken, welches Ziel angestrebt wird. Erst dann macht es Sinn, eine Produktauswahl zu treffen.
Wir, die TCC, empfehlen als Zielvorgabe einen Lösungsansatz, der ein Event- und Performancemonitoring verlangt.
Dienste, SLAs, Server und aktive Geräte sollen ganzheitlich überwacht werden. Auftretende Events in heterogenen Netzwerken sollen regelbasiert behandelt werden und entsprechend ihren individuellen Anforderungen Alarme auslösen.
Dies muss
- Überwachung beliebiger Geräteeigenschaften per SNMP, WMI
- Traffic- und Performancemonitoring
- Regelbasierte Sensoren zur Behandlung von kritischen Zuständen
- bieten. Sämtliche in der CMDB verfügbaren Informationen sollen überwacht werden.
Das Monitoringsystem soll über eine integrierte CMDB verfügen. Alle zu überwachenden Komponenten und Dienste sollen hier abgelegt werden. Kern der Lösung müssen regelbasierte Software Sensoren sein, die u. a. einzelnen Geräte, Werte, Dienste regelbasiert überwachen. Regelbasiert heißt, dass hier für jeden Sensor Regeln frei definiert vergeben werden können und abhängige Verknüpfungen der Sensoren untereinander auch komplexe Zusammenhänge überwachbar machen. So können auch aufeinander aufbauende Fehler frühzeitig erkannt und klassifiziert werden. Im Idealfall möchte man früh erkennen, ob und wo sich ein größerer Ausfall ankündigt.
Ein einfaches Beispiel zeigt die Tragweite kleiner Fehler:
bei einem Kunden wurde bei Wartungsarbeiten an einem Router das Bandbreitenmanagement zwischen zwei Standorten verändert. Die Folgen waren: Druckaufträge, die zwischen Standort 1 und 2 benötigte die ganze Bandbreite und verhinderte somit eine Telekommunikationsmöglichkeit, da die Brandbreite bereits voll ausgelastet war.
Ein Sensor hätte die Veränderung am Bandbreitenmanagement erkannt und gemeldet. So hat die Fehlerbehebung einige Tage gedauert, weil zunächst nicht klar war, wo die Ursache des Telefonieausfalls eines Standortes lag. Eine fatale Situation, da der Anwender Telefoniedienstleistungen verkauft und so teilweise nicht produktiv war.
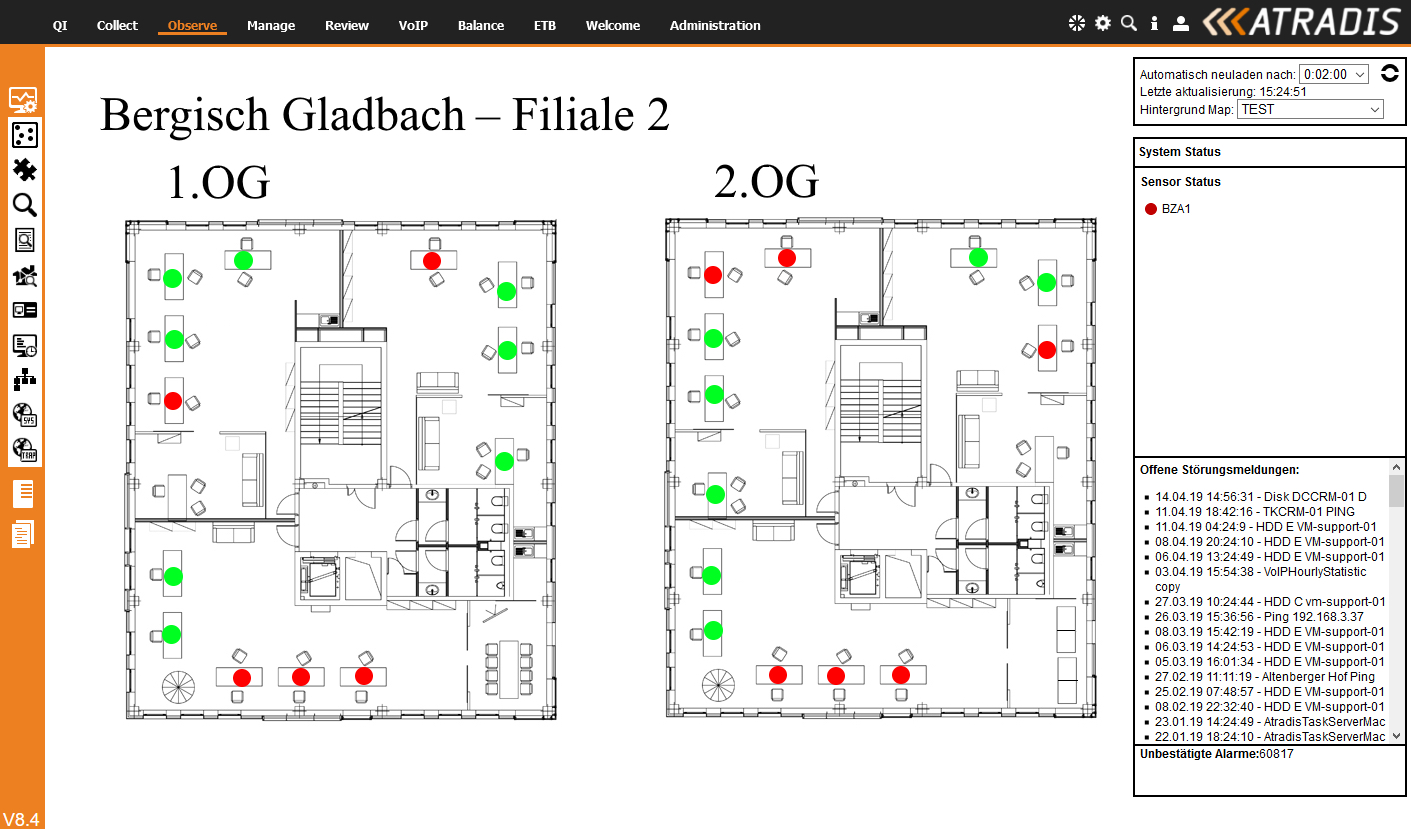
Hat man im Rahmen der IT-Sicherheitsanalyse systemkritische Punkte erkannt, so sind diese mit Sensoren leicht zu überwachen.
Alle SNMP- oder WMI-fähigen Komponenten sollen im Rahmen des Monitorings überwacht werden. Die zu beobachtenden Werte müssen zyklisch abgefragt werden. Bei Abweichung von einem vordefinierten Bezugswert, müssen Ereignisse (Aktionen) ausgelöst werden können. Das Monitoring muss auf einem flexiblen Framework basieren, welches einfach an die Kundenbelange anpassbar ist. Ein Basisregelwerk sollte mit ausgeliefert werden.
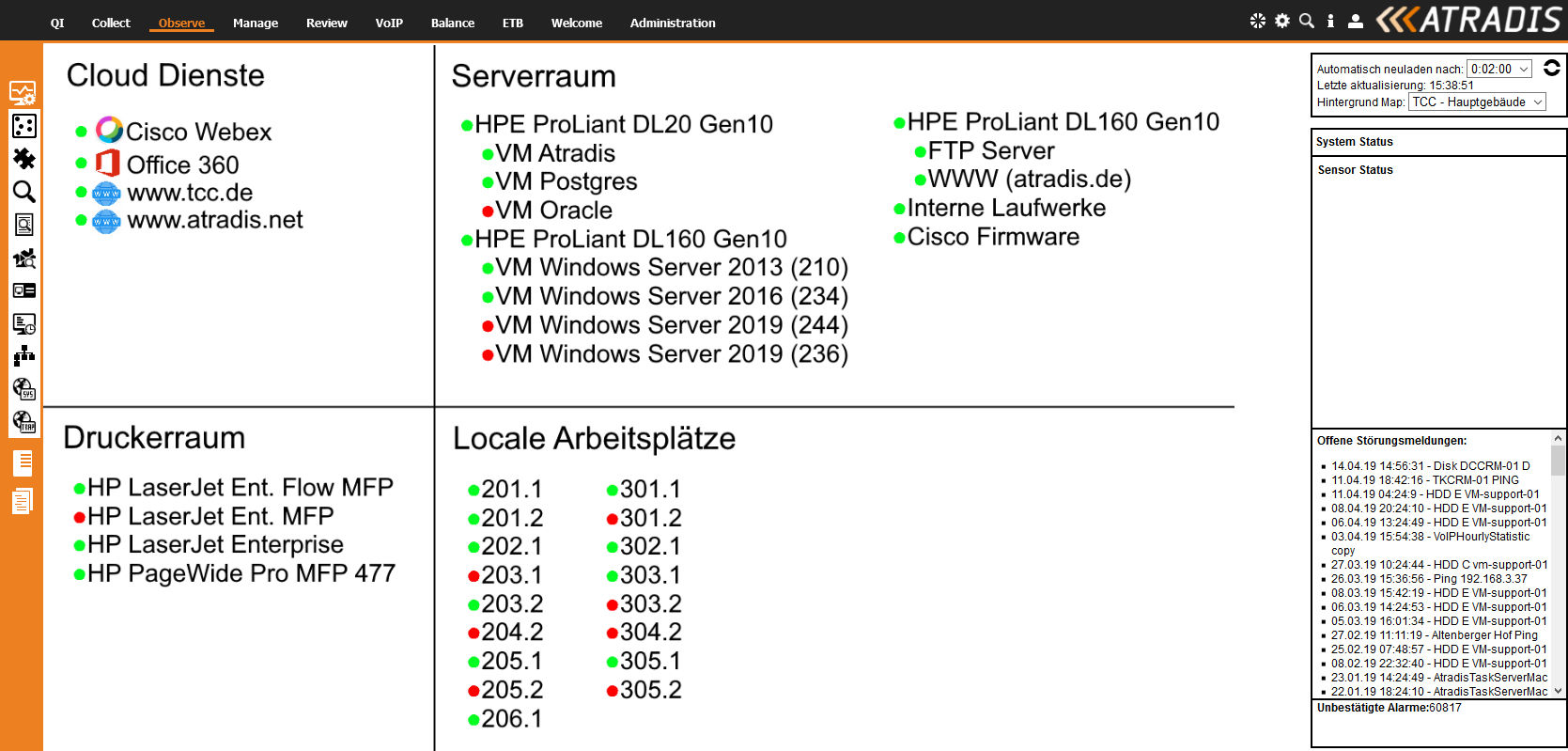
Das einzusetzende Monitoringsystem soll eine regelmäßige Überwachung des Netzes ermöglichen, um neue Clients im Netz aufzufinden. Damit können unerwünschte Netzclients identifiziert und lokalisiert werden.
Wünschenswert ist eine Assetmanagement Komponente. Sie soll die Erfassung von zusätzlichen Informationen zu aktiven Netzwerkobjekten ermöglichen und diese unterstützen. Hierbei steht die automatische Abfrage der Informationen zu Geräten im Vordergrund. Mit Hilfe eines AutoDiscoverys soll das Netzwerk durchsucht und Daten zu allen gefundenen Komponenten gespeichert werden.
Hierzu muss eine leistungsfähige Scanengine zur Verfügung stehen, die zyklischen Subnetze oder komplette Netzwerke abfragt. Der Zyklus muss flexibel einstellbar sein. Die Netzlast für Standardabfragen muss durch den Einsatz moderner Grid-Technologie geringgehalten werden und eine parallele Abfrage möglich sein.
Ein flexibles Dashboard, dass den Administratoren aber auch dem Management zusammenfassende Informationen über den Gesamtzustand der überwachten Systemtechnik liefert, sollte Bestandteil der Lösung sein. Mittels einer einfachen Drill Down Funktion, sollte man sehr schnell die benötigten Detailinformationen erhalten.
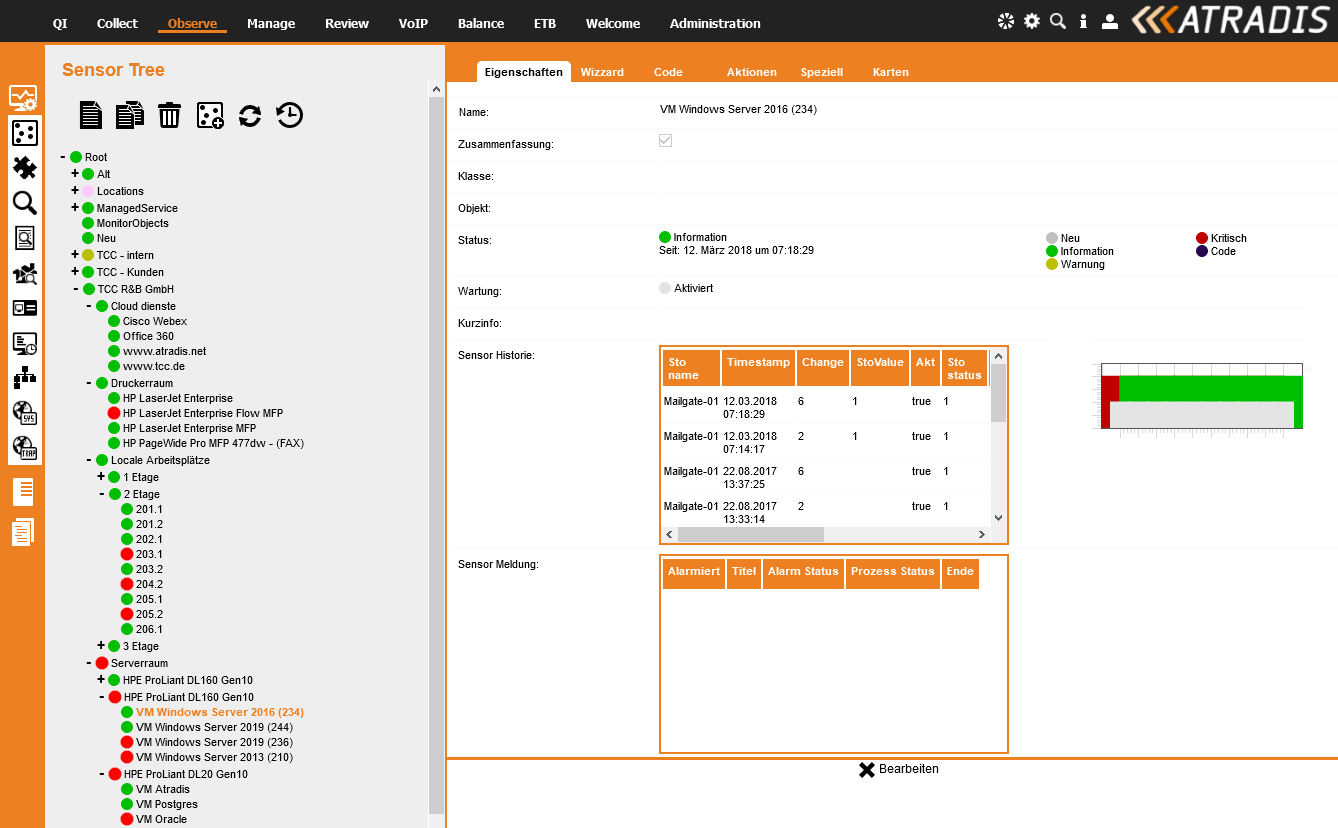
Die TCC GmbH stellt mit dem Produkt ATRADIS<Observe eine Software bereit, die die oben beschriebenen Anforderungen komplett erfüllt. ATRADIS<Observe ist einfach zu installieren und zu betreiben. Das Produkt steht sowohl als Kaufversion, als auch als SaaS (Software as a Service) Version zur Verfügung.
Das TCC Team bietet Unterstützung bei der Implementierung, der Datenerfassung und den Anwendertrainings an.